COVID-19 got me thinking about trend lines and the different ways people generate and interpret them. This is a question that’s of course more general than just COVID-19, but let me use this as an example to explain some very basic principles. This post is motivated by discussions I have had with a number of journalists, including Chad Skelton who nerd-sniped me into writing a post on trend lines and a thread discussing trend lines with Roberto Rocha and Tom Cardoso.
Why trend lines
Data is inherently noisy, trend lines are a way to filter out noise and focus on the main movements of a time series. “Are we trending up or down?” is a simple yet important question, but it can be hard to answer by just looking at the raw data. In that sense a trend line is simply a way to de-noise the data.
But how do we distinguish noise from the “real” signal in the data? First we need to understand the “data generating process”. In case of COVID-19 timelines that’s viral growth, so we expect the main signal of our time series to be exponential growth with periods of constant growth rates, with noise added on top of that. (This can also be tested directly by running tests on the COVID-19 cases time series.)
Semi-log plots
At the beginning of the pandemic John Burn-Murdoch at the Financial Times popularized semi-log plots that elegantly incorporate this basic insight into the data generating process, periods of constant (exponential) growth rates show up as straight lines on a semi-log plot, making it easy and intuitive to see if countries were “bending the curve” (i.e. reducing their growth rate). The plots can also serve as forecasting models by people simply mentally extending the (straight) lines.
However, while the semi-log plots helped people to understand doubling times, people were still shocked how fast daily case numbers were piling up. It does not solve the fundamental problem that a lot of people don’t have an intuitive understanding of exponential growth. Plus this kind of visualization became less useful once countries bend the curve and reduced daily case counts to much lower levels, followed again by periods of rising cases.
And semi-log plots still don’t solve the problem of how to remove noise, even if human brains are good at mentally adding a line through a noisy set of points, intuiting a trend line.
Trend lines
One way to de-noise COVID-19 timelines that gets a lot of use is to use moving averages. This approach simply replaces each data point with the average taken in within a window around that point. There are several fundamental problems with this approach.
- Moving averages introduce a time lag
- Moving averages disrespect the data generating process
- Moving averages are not very good at smoothing
To understand this, consider the following synthetic example of a timeline with exponential growth followed by exponential decline, with (multiplicative) random (normally distributed) noise. We generate 100 data points and show three different types of moving averages, plus an STL trend line which we will explain in more detail later.
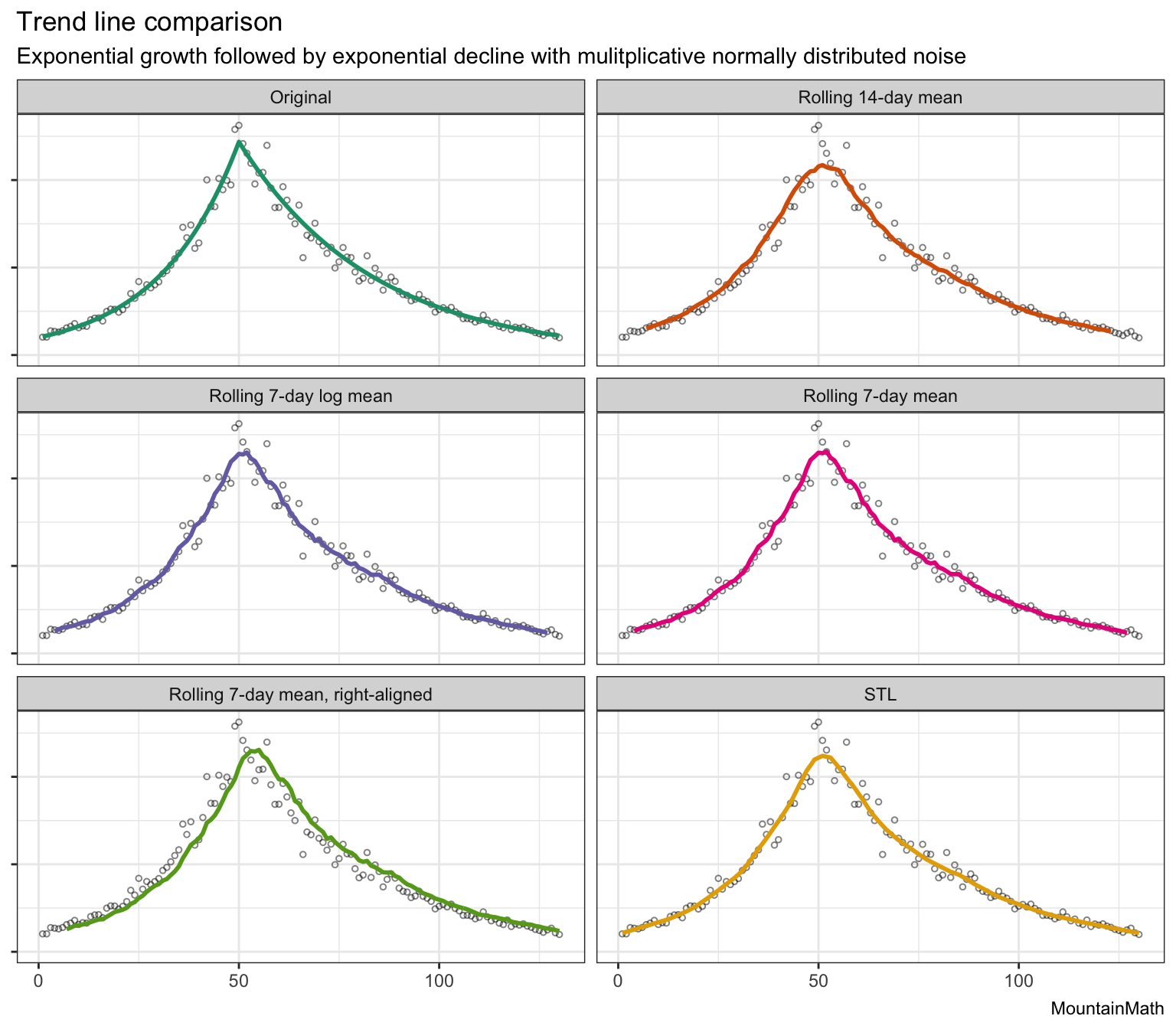
The first thing we notice is that moving averages lag. 7-day averages lag by 3 days, 14 day averages lag by 7 days. That’s ok if we aren’t that interested in the most recent trends, but is a problem if recent trends are the focus.
Sometimes people “solve” this problem by shifting the trend line to the right, as shown in the “right-aligned” example above, which makes the problem of the lag less obvious. But of course this introduces a new problem, non-data oriented viewers will misinterpret the shifted trend line as not having a lag, and the shifted trend line representing the actual trend. In short, shifting the moving average is quite misleading. This is particularly problematic if the shifted moving average is overlayed over case count data.
Another problem with moving averages is that it’s not a good idea to take averages when the data generating process is multiplicative. This has the effect that moving averages systematically under-estimate the trend line during growth periods and over-estimates it during periods of decline. This can be fixed by first taking logs before averaging (and then exponentiating again).
Lastly, the moving averages do a poor job at removing noise. We still see a lot of wiggles, especially in the 7 day moving averages, that have nothing to do with the underlying trend. Taking wider averaging windows can help with that, but we loose temporal resolution of trends and most importantly increase the lag.
All of this can be seen much more clearly on a semi-log plot.
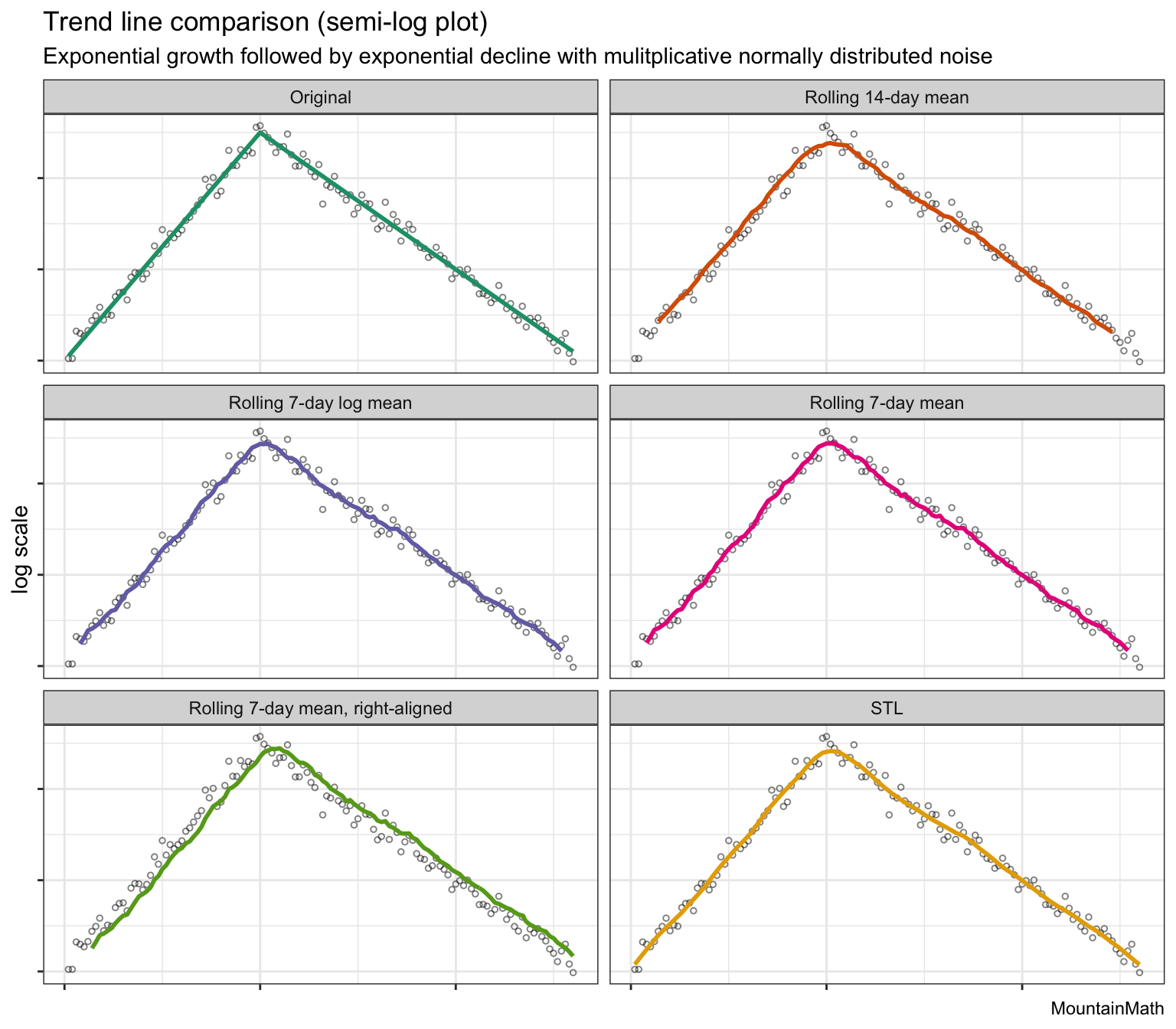
Which leaves us with the question of what we should be using, if not rolling averages. But before we get there, we need to look at one other source of noise that we see in COVID-19 data: a very strong weekly pattern.
Weekly patterns and seasonal adjustments
It is now common knowledge that COVID-19 timelines show a strong weekly pattern that can distract from spotting underlying patterns. This can be easily verified by testing the time series for seasonality. The choice of window size in rolling averages is informed by that and is thus chosen as (a multiple of) 7 days. Sometimes commenters interested in less laggy metrics will take week over week differences in daily case counts to discern trends. The existence of this weekly trend tells us that we should model the daily case counts as made up of a trend line, a weekly pattern and random noise. And the weekly pattern is relatively large, accounting for this is essential when determining trend lines. To complicate things, the weekly pattern itself is also time-varying, the pattern we saw earlier in the pandemic is different from the pattern we are seeing today. Fortunately this problem is not unique to COVID data, and there is a wealth of well-established methods to deal with time series decompositions into trend, seasonal pattern, and random noise. (Here seasonality is a technical term that refers to the main mode of the repeating pattern in the de-trended time series, in this case 7-days.) Accounting for seasonality sounds like a big thing, but we do this all the time when dealing with time series. For example, Statistics Canada does exactly this for many of their time series and publish a “seasonally adjusted” version. Time to try out some methods using real COVID-19 data.
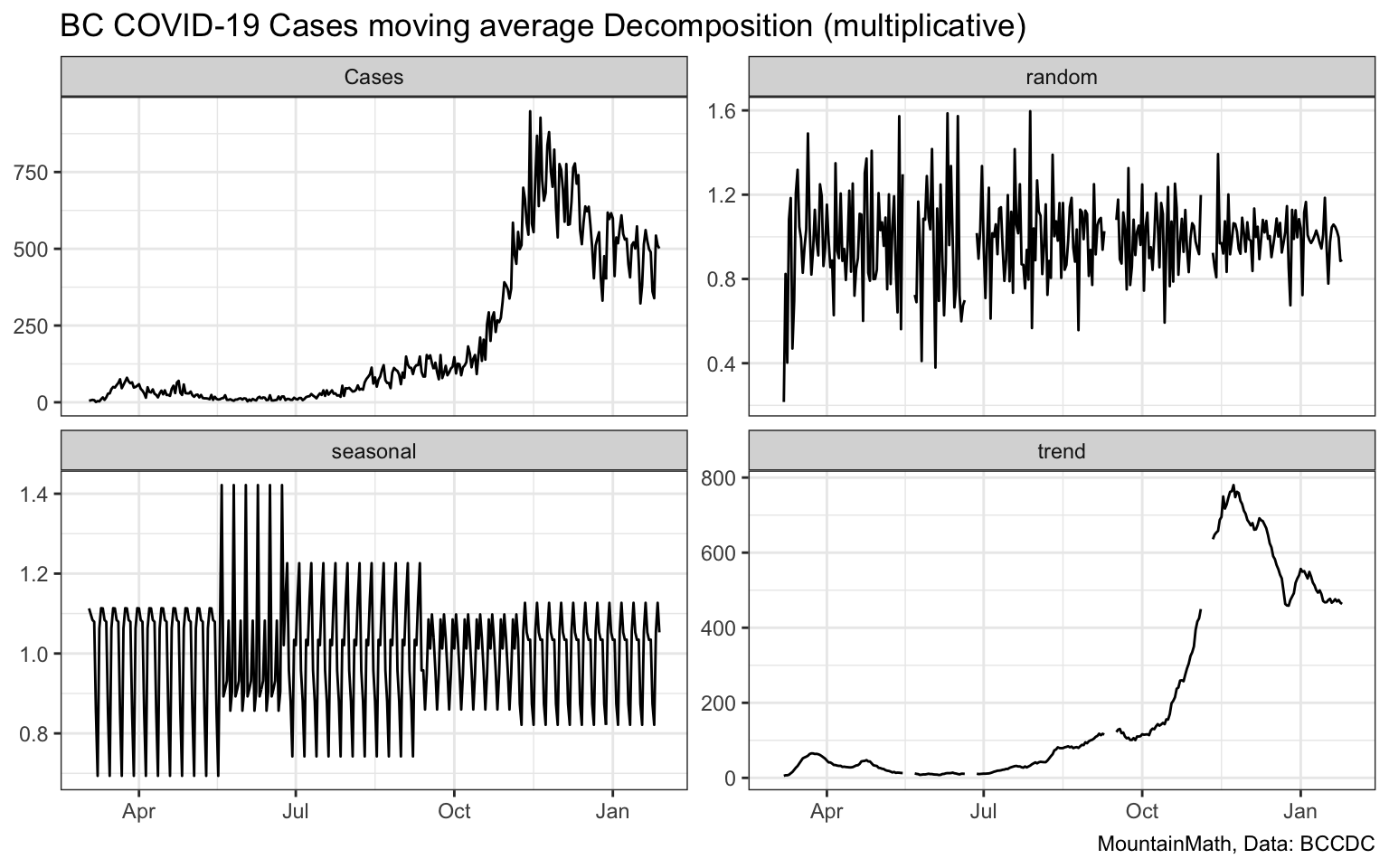
To start out we use a decomposition based on moving averages. That is we first determine the trend line using moving 7-day averages, and then compute the seasonal pattern by averaging over the residuals for each day of the week, and interpret the remaining residual as random noise. This decomposition will generate the exact same trend line as our moving average above and suffer from the same time lag problem. What this will do is help us better understand the problems with moving averages.
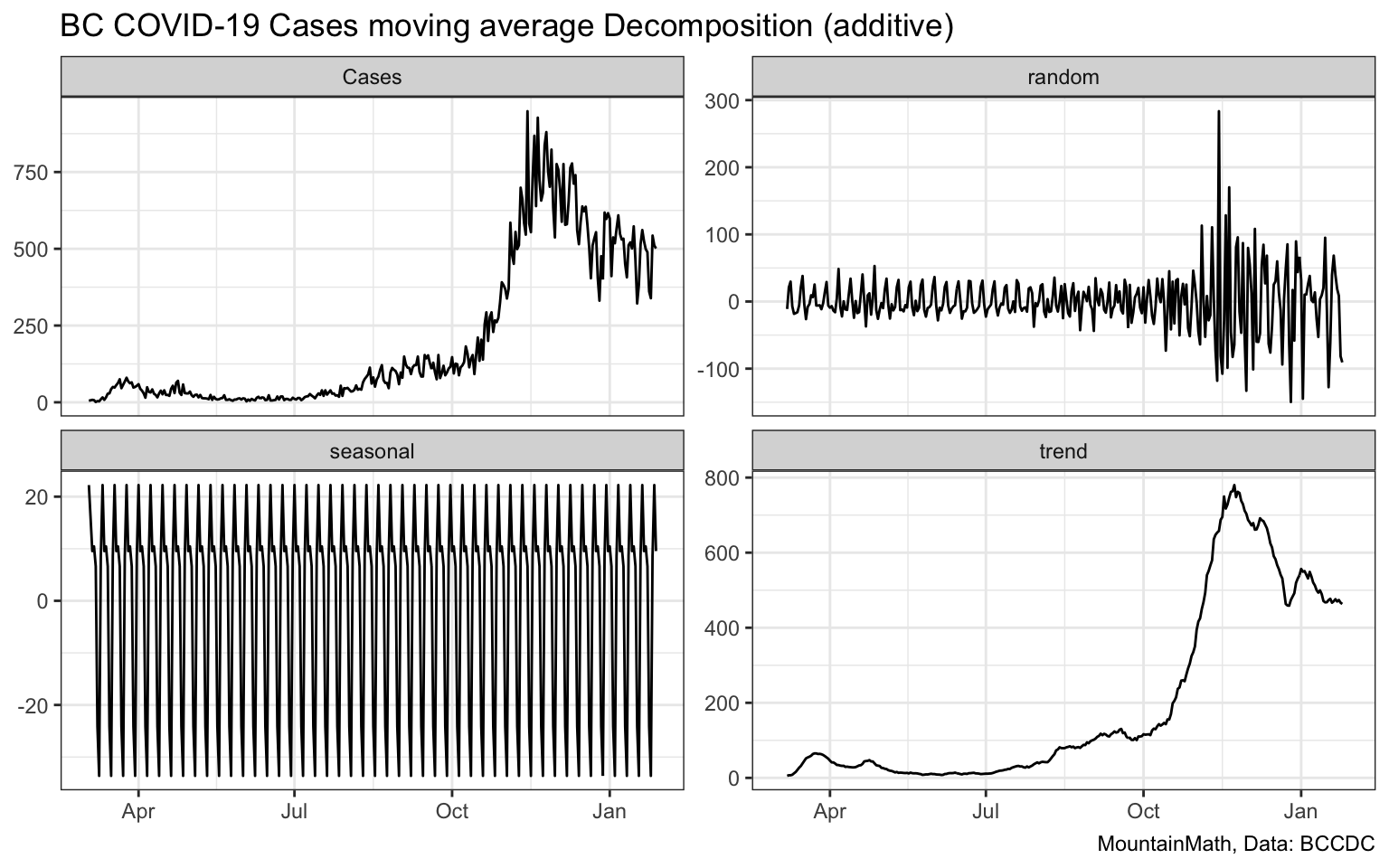
We notice that the random component varies strongly with the case numbers, when case numbers are relatively now the random component is low, when case numbers are high the random component is large. This tells us right away that we should not choose an additive model.
To verify this we can choose a multiplicative decomposition that models seasonal and random components as multiplicative (rather than additive) components of cases.
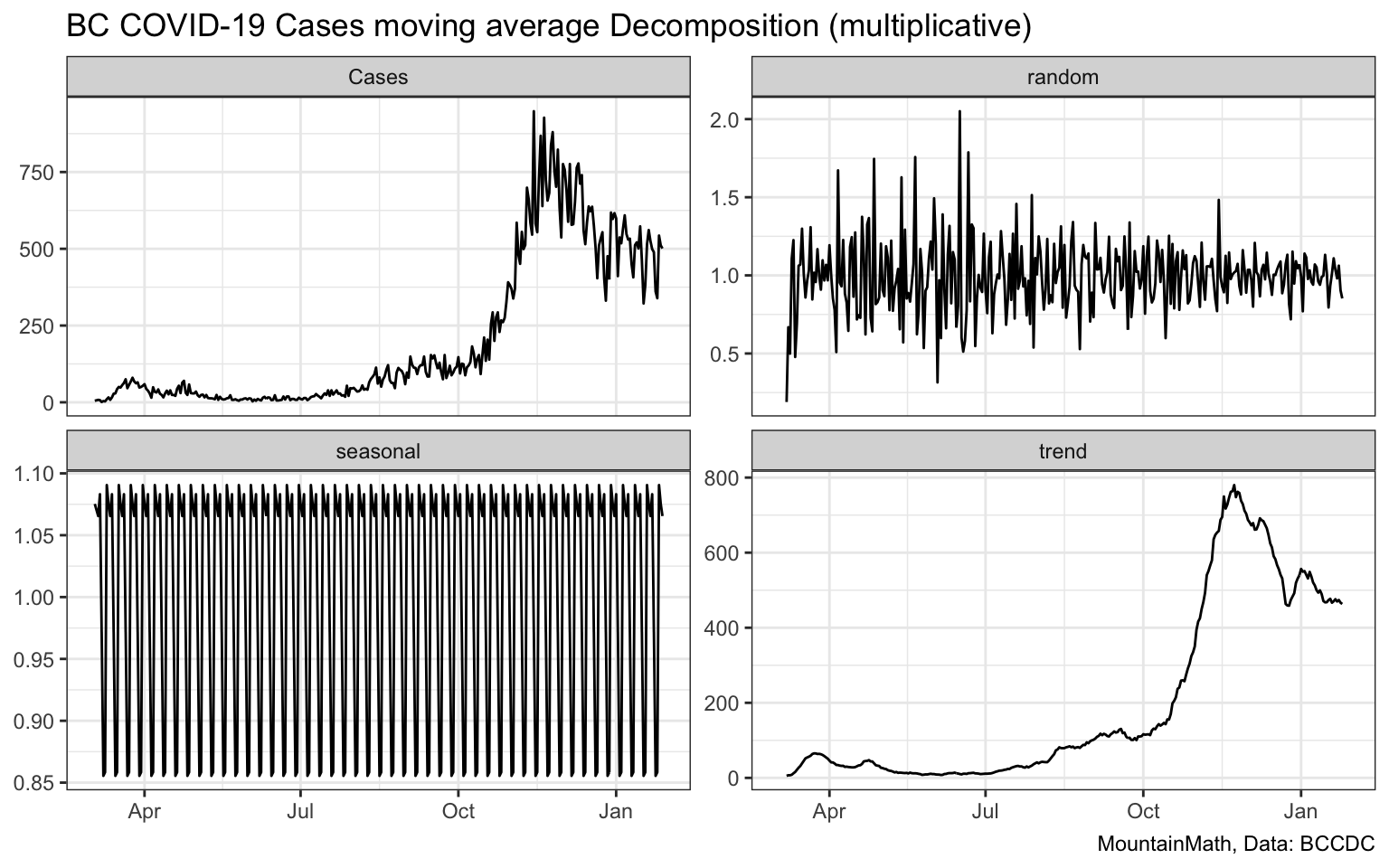
The trend line is identical to the previous version, but the random component now looks much more regular. It is larger early in the pandemic, which we should expect as our testing was not very consistent at that time.
What this allows us to do is also show a seasonally-adjusted timeline, taking out the expected weekly variation.
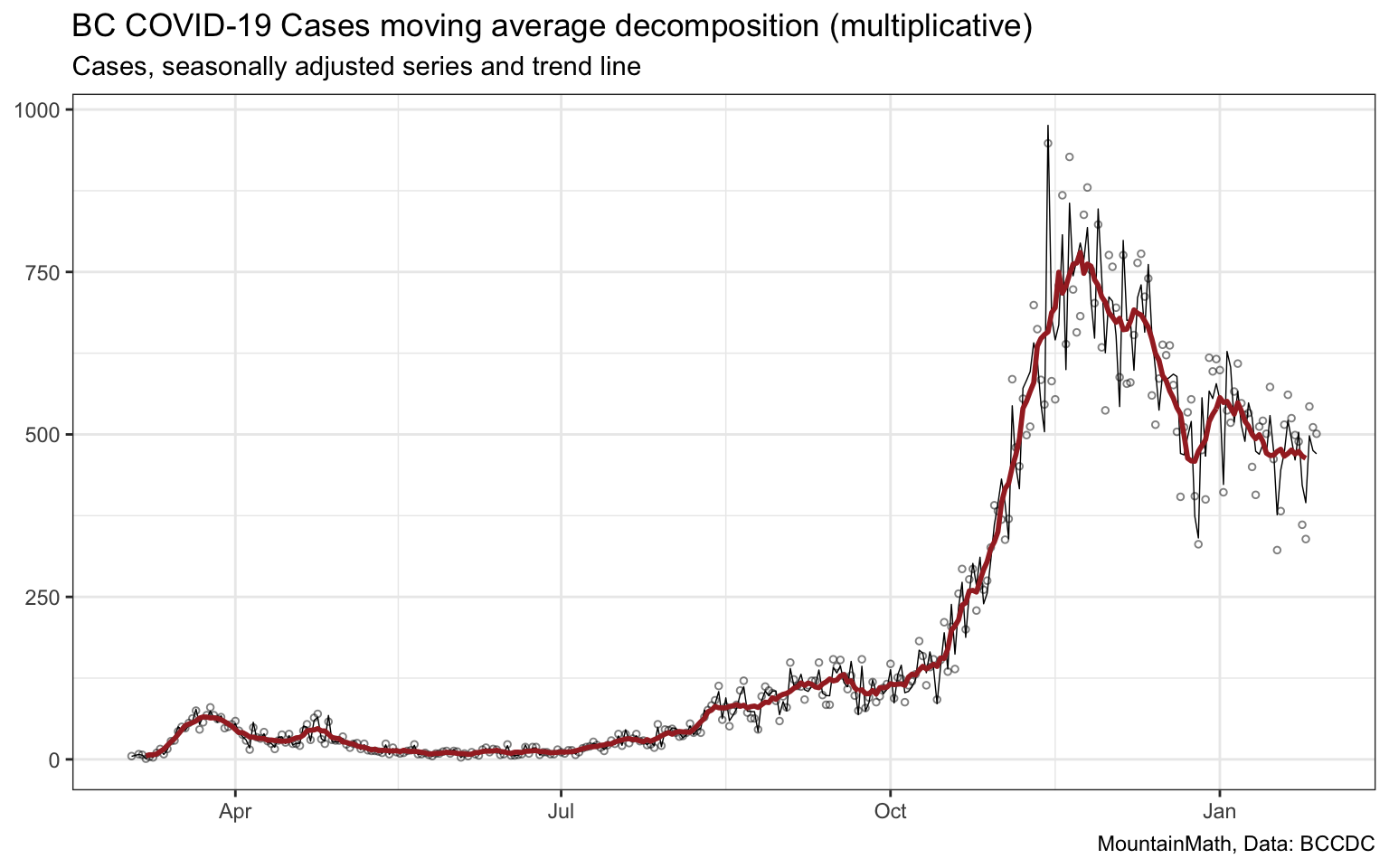
The seasonal decomposition gives us a better way to think about by how much individual day case counts are above or below the moving average under consideration of the weekly variation in case counts. In particular we notice how the raw case counts (circles) are more noisy than the seasonally adjusted (black) line that remove the weekly pattern from the raw data. Which adds some insight, but still leaves several problems. One is that we still have a 3-day time lag, which further delays our response if we use moving averages as a guide. The other is that the seasonal pattern changes over time. To see this, we divide our time series up into several intervals, using the “phases” identified by the BCCDC as a guide, and compute the decomposition separately for each.
This way of slicing the data into different phases is very naive, but we see clear differences in the seasonal pattern the decomposition picked up in the different phases. And more importantly, it managed to reduce the size of the “random” component, or in other words, the seasonal pattern and trend line better describe the case data when we fit the seasonal pattern to sub-intervals of our timeline. The trend line will now show 6 day gaps where we broke up the time intervals, missing three days on each end. And the trend line still shows features that look more like noise than signal. We are on the right track, but we need some slightly more sophisticated tools.
STL decomposion
Lots of ink has been spilled on time series decomposition, for this post we will focus on STL decomposition which in our view is a good compromise between simplicity and effectiveness when dealing with COVID-19 timelines.
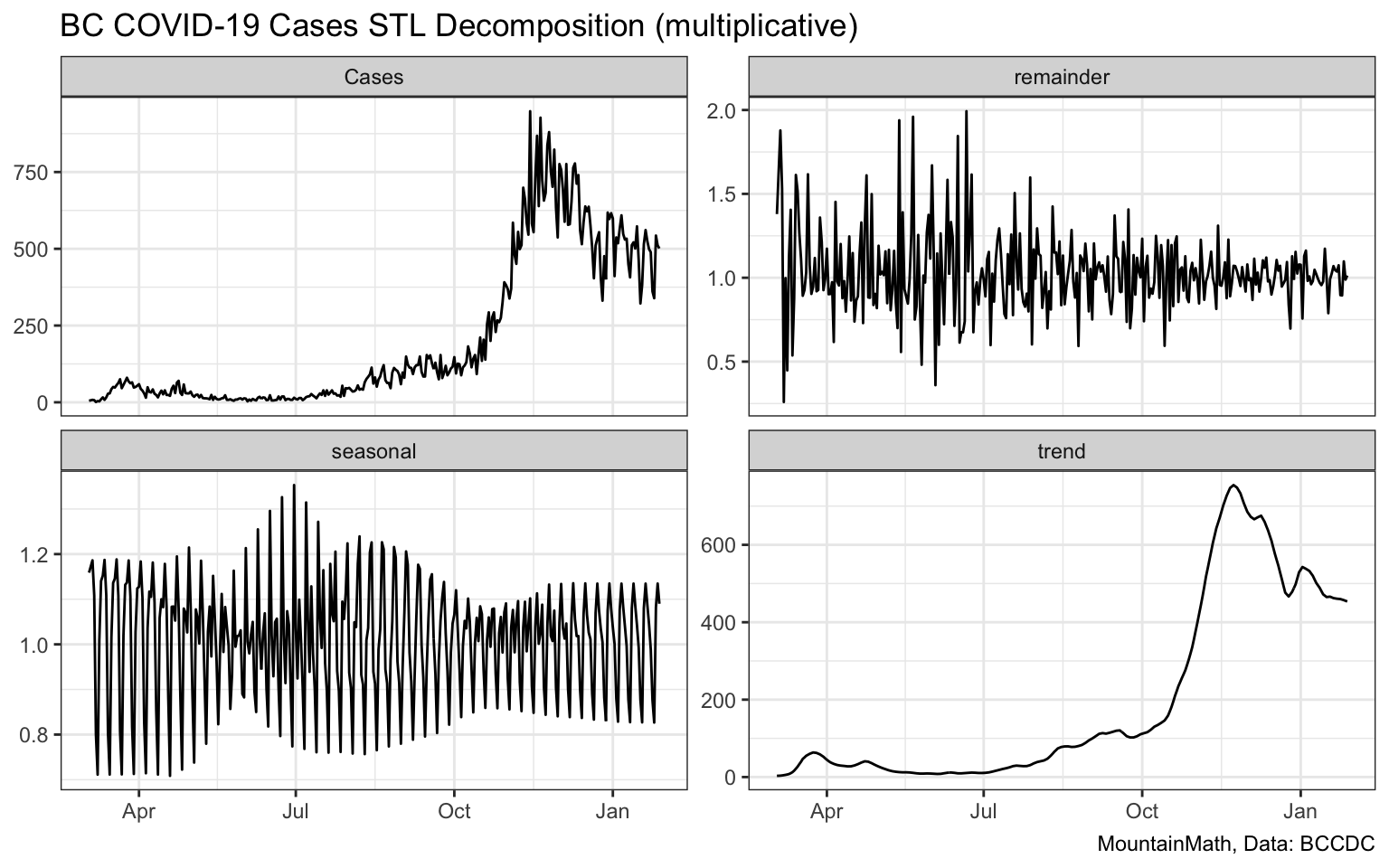
As a result we have
- a cleaned trend that lacks obvious signs of random noise
- a trend line that has no lag and also covers the most recent days
- a varying seasonal pattern
- a remainder that has not suffered much by increasing smoothing in the trend
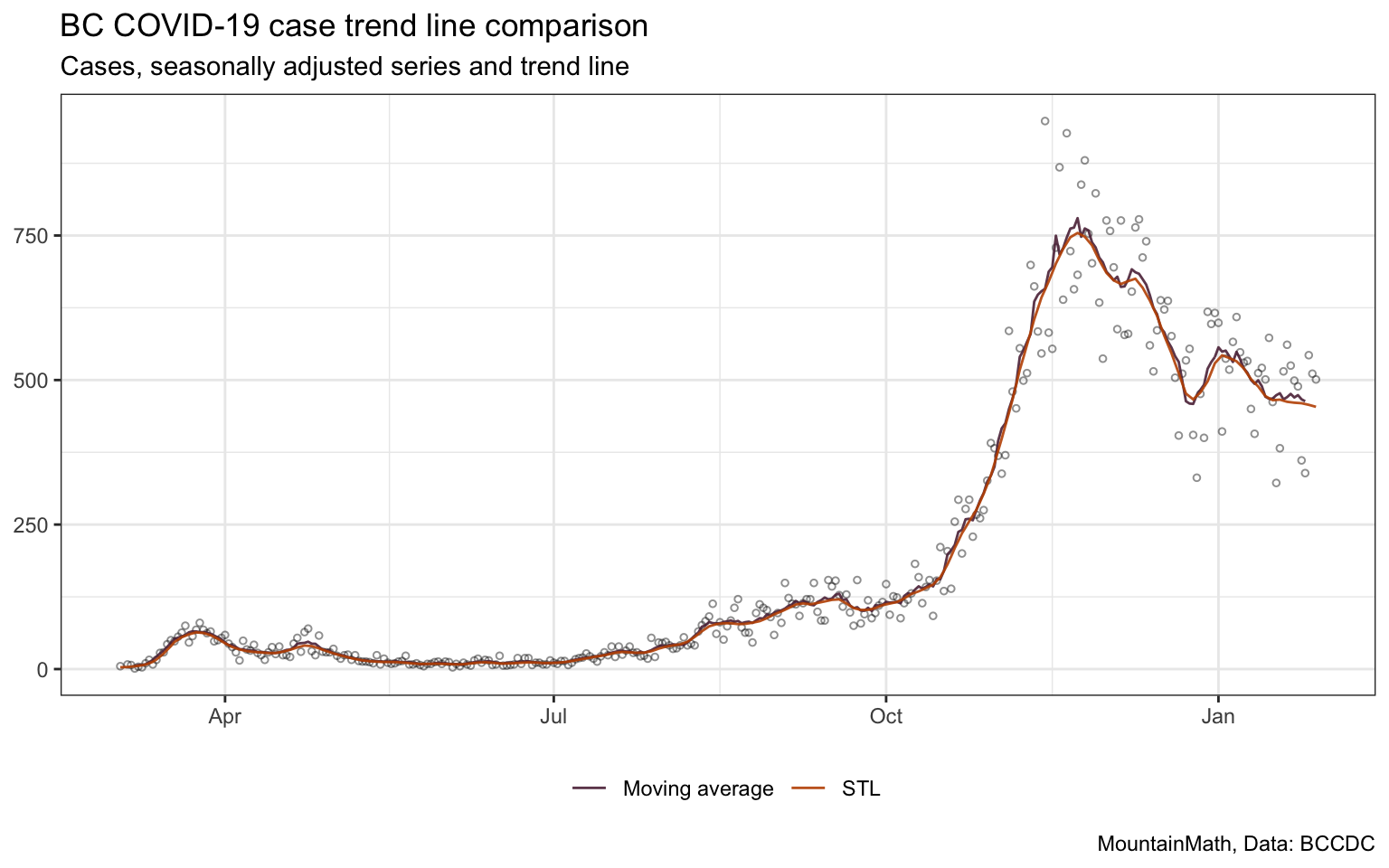
The difference between these two methods is not large, but it’s noticeable. The STL decomposition manages to remove more noise, and most importantly, give an estimate of the trend for the most recent three days too. Accounting for the weekly seasonality is essential for this.
I won’t go into details how the sausage is made, in broad strokes STL is an iterative process of fitting a Loess trend and estimating the seasonal component.
One disadvantage of STL trend lines is that new data can wiggle the last data points. Smoothing and the estimation of the seasonal component happens in both forward and backward time, so new data can impact the tail of the curve. The effect will generally be small, but it is something to watch out for.
Right censoring
Unfortunately, no discussion on covid data can be complete without talking about right-censoring of data. The issue is that COVID-19 data systems often lag. The common understanding is that case data get reported each day, and we expand our time series day by day as we add new cases. But unfortunately that’s not how it works. For reasons not clear to me, each new data release wiggles a bunch of data points for previous days, often even for days several months back.
More importantly this is especially acute for the most recent day, which typically gets a bunch of extra cases as new data comes in. What this means for trend lines is that the tail is systematically biased down. We have not explored this systematically, but here are some typical examples of differences in case count between two recent consecutive days.
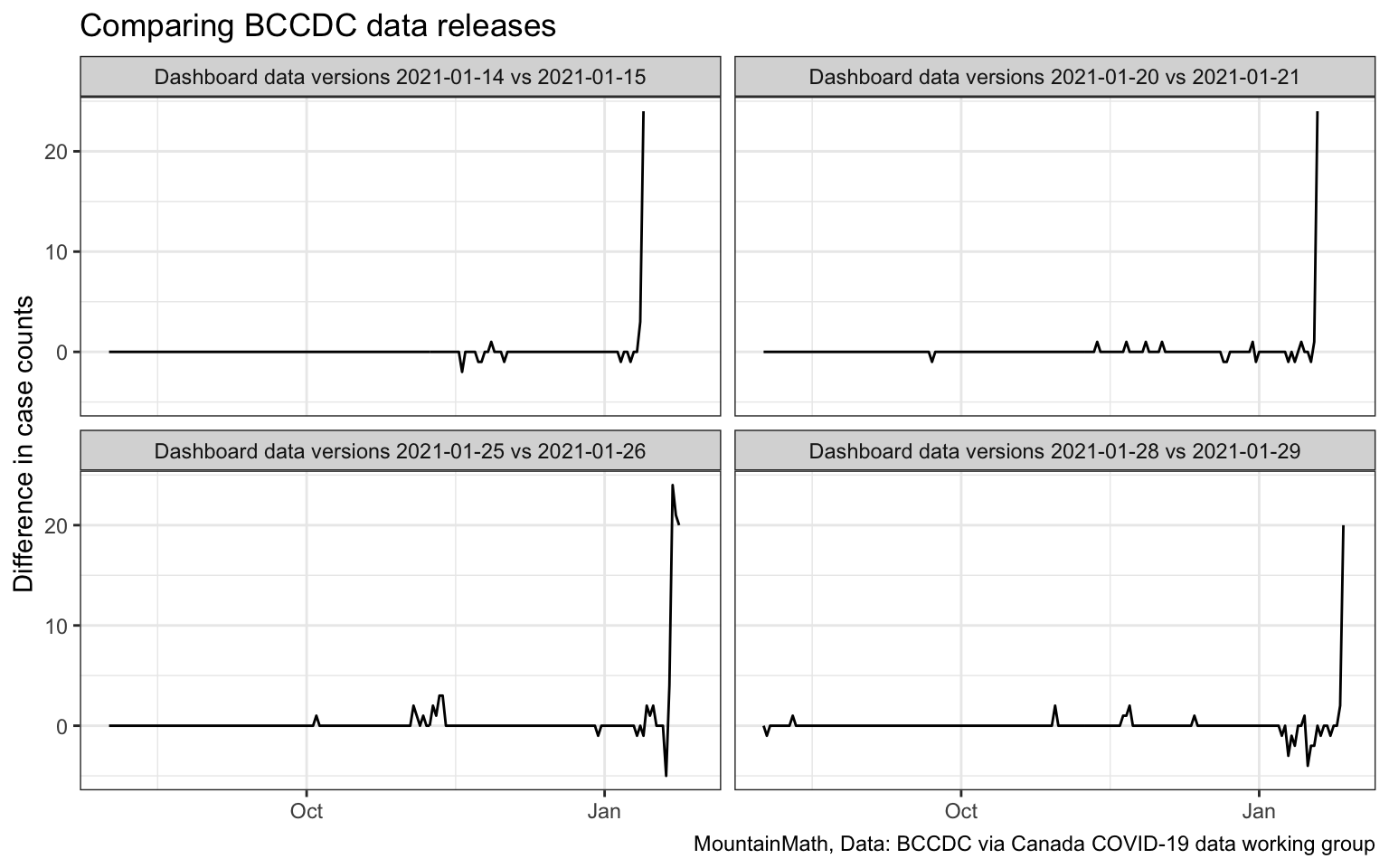
During the past few weeks, frequently about 20 cases have been added to the most recent day as new data comes in. Additionally cases get added or shifted around for earlier dates. This is obviously problematic. On January 7 BCCDC announced that they were switching over to a new data system that was getting case data directly from the labs, which would result in more timely and better quality data. Which it did. But data issues still remain, and it’s frustrating that these aren’t openly discussed and documented, but instead left for everyone who uses the data to discover for themselves.
We visualize the effect of the right-censoring on the end of the tail of the data series for the dates we used above.
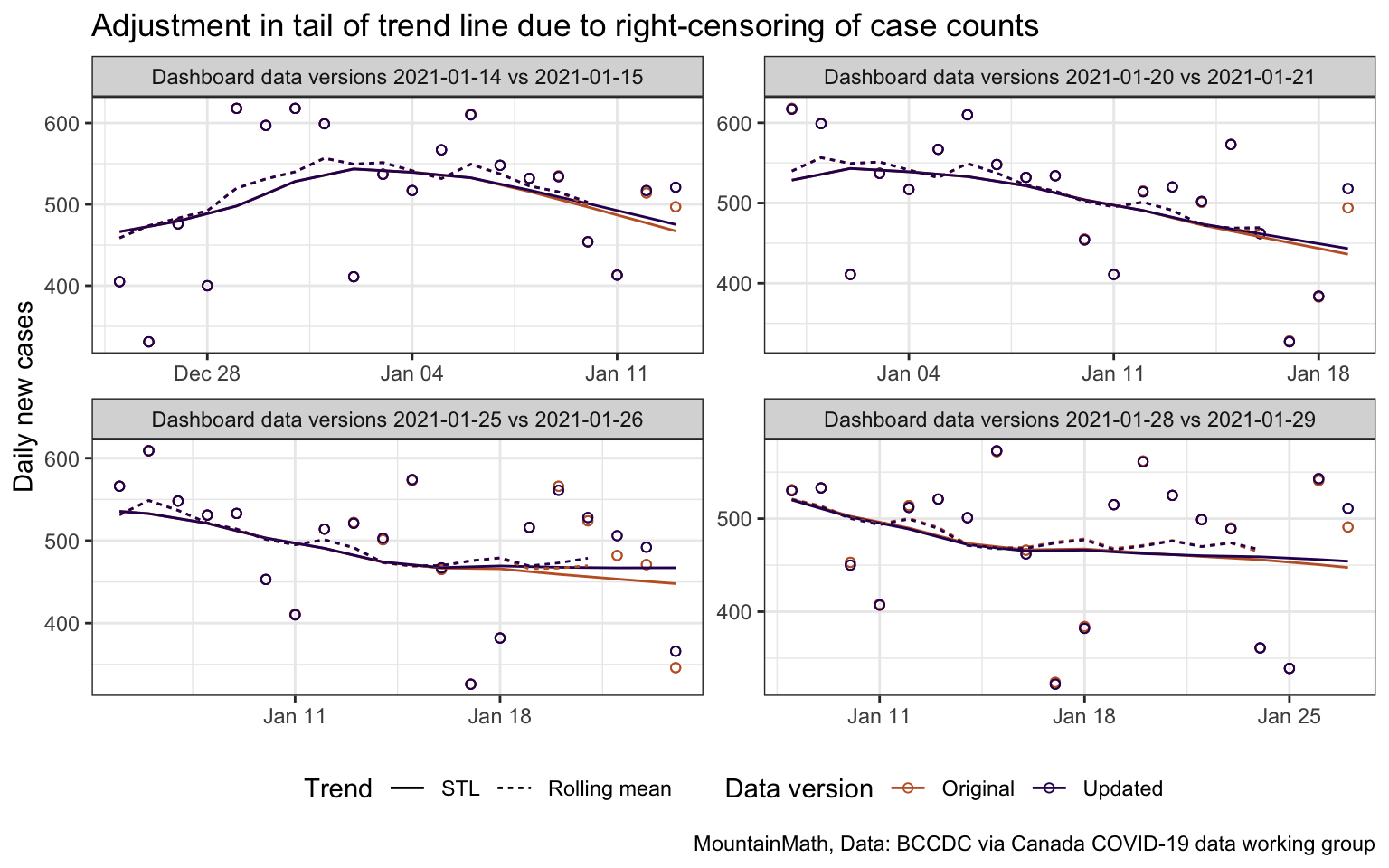
The effect of the right-censoring is clearly visible in the STL trend lines. It also shows up in the moving averages that we added as dashed lines, but it is less pronounced as the moving average lags by three days. We do not adjust for this effect in our auto-updating STL trend lines for BC. However, doing so would be prudent for modelling applications, in particular ones that put extra emphasis on recent trends to derive their forecasts.
The same kind of right-censoring happens in a much more severe way when looking at data by symptom onset, as for example Island Health does. Showing data by symptom onset can be very useful for analysis, but it is a very poor choice for a “dashboard” where people come to look for how things are going. The (weirdly overlapping) bar graph is the only graphical representation of case counts on the Island Health dashboard, and this will likely lead quite a few people to believe that cases have come down recently when this is entirely due to right-censoring and the opposite is the case.
Right-censoring can be avoided to some extent by adopting the “journalist’s case counts” instead of using dashboard case counts. The “journalist’s counts” are the case numbers announced in the news briefings. There is no digital data on this, the numbers have to be manually assembled into time lines, and each release contains the cumulative count for that day, including the part (if any) that gets re-distributed over previous days. The resulting timeline trades long-run accuracy for avoiding right-censoring in the short-run. I was hoping that the new BCCDC data system would avoid the right-censoring and both timelines would merge, but unfortunately that does not seem to be the case.
Upshot
Trend lines are important for understanding where we are, how we got there and getting an indication of the direction of where things are going. They are quick and easy to do and involve minimal outside choices. As such they are a very useful descriptive scaffolding for understanding time series.
Moving averages are one possible choice, but they add extra lag and need to be used responsibly. Right-aligned moving averages should be avoided as they hide the data lag which is often not obvious to the audience and can thus be misleading. In the case of COVID-19 data, moving averages don’t respect the data generating process and will lead to systematic under- and overestimates during periods of rising or falling cases, respectively. Moving averages are also not very good at removing all noise. The saving grace for rolling averages is that they are stable when new data comes in, existing values won’t change. That’s the tradeoff for the extra data lag.
The simplicity of moving averages is another appeal, most people will understand how it’s derived. This is particularly important when data is to be used to trigger public health interventions. In cases like this it can be very useful to use a rolling sum instead of a rolling average, that avoids the misinterpretation as a trend line and the triggers for public health measures can be encoded in terms of rolling sums. This is exactly how the 7-day incidence metric, the cumulative cases in the past 7 days per 100k population, works in Germany. It’s easy to understand, does not change as new data comes in (assuming data processes are reasonably clean and right-censoring is minimal) and makes anti-COVID measures predictable. For example, German guidelines call for all children to wear masks in schools at all times when the regional 7-day incidence rises above 50, and for older children the cutoff is at 35.
We feel that STL decompositions give a good balance between simplicity and effectiveness for trend lines. Choosing a multiplicative decomposition is useful to more closely model the data generating process. STL trend lines have a superior smoothing compared to moving averages, making it easier to spot underlying trends. At the same time, the incorporation of seasonal adjustment allows to remove the weekly signal, find better trend lines, and also give good estimates of the trend line for the most recent days, removing the data lag that plagues moving averages. If data is exceptionally noisy, STL can be tuned to be robust against outliers.
There are several ways to improve on STL trend lines. Pure time series models like ARIMA attempt to extract information from the random component, which may hold patterns that we have not used in the STL decomposition. At that point it would probably be better to choose a more structured model and directly model viral spread.
While models of viral spread are extremely useful, they leave the world of descriptive analysis. Models of viral spread involve a myriad of choices and the results will be model dependent. Fitting the models can be computationally intensive, which can add a different kind of lag. Ideally we would use simple descriptive STL decompositions for quick visual checks on trend lines and communication purposes, and fit an ensemble of viral models to gain deeper understanding, as well as for forecasting purposes.
As usual, the code for this post available on GitHub in case anyone wants to reproduce or adapt it.
Reproducibility receipt
## [1] "2021-01-30 21:51:34 PST"## Local: master /Users/jens/Google Drive/R/mountaindoodles
## Remote: master @ origin (https://github.com/mountainMath/doodles.git)
## Head: [73cb8fa] 2021-01-31: covid trend lines## R version 4.0.3 (2020-10-10)
## Platform: x86_64-apple-darwin17.0 (64-bit)
## Running under: macOS Big Sur 10.16
##
## Matrix products: default
## BLAS: /Library/Frameworks/R.framework/Versions/4.0/Resources/lib/libRblas.dylib
## LAPACK: /Library/Frameworks/R.framework/Versions/4.0/Resources/lib/libRlapack.dylib
##
## locale:
## [1] en_CA.UTF-8/en_CA.UTF-8/en_CA.UTF-8/C/en_CA.UTF-8/en_CA.UTF-8
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] forcats_0.5.0 stringr_1.4.0 dplyr_1.0.3 purrr_0.3.4
## [5] readr_1.4.0 tidyr_1.1.2 tibble_3.0.4 ggplot2_3.3.3
## [9] tidyverse_1.3.0
##
## loaded via a namespace (and not attached):
## [1] Rcpp_1.0.5 git2r_0.27.1 cellranger_1.1.0 pillar_1.4.7
## [5] compiler_4.0.3 dbplyr_1.4.4 tools_4.0.3 digest_0.6.27
## [9] lubridate_1.7.9.2 jsonlite_1.7.2 evaluate_0.14 lifecycle_0.2.0
## [13] gtable_0.3.0 pkgconfig_2.0.3 rlang_0.4.9 reprex_0.3.0
## [17] cli_2.2.0 rstudioapi_0.13 DBI_1.1.0 yaml_2.2.1
## [21] blogdown_0.19 haven_2.3.1 xfun_0.18 withr_2.3.0
## [25] xml2_1.3.2 httr_1.4.2 knitr_1.30 fs_1.4.1
## [29] hms_0.5.3 generics_0.1.0 vctrs_0.3.5 grid_4.0.3
## [33] tidyselect_1.1.0 glue_1.4.2 R6_2.5.0 fansi_0.4.1
## [37] readxl_1.3.1 rmarkdown_2.5 bookdown_0.19 modelr_0.1.8
## [41] blob_1.2.1 magrittr_2.0.1 backports_1.2.0 scales_1.1.1
## [45] ellipsis_0.3.1 htmltools_0.5.0 rvest_0.3.6 assertthat_0.2.1
## [49] colorspace_2.0-0 stringi_1.5.3 munsell_0.5.0 broom_0.7.4
## [53] crayon_1.3.4Reuse
Citation
@misc{on-covid-trend-lines.2021,
author = {{von Bergmann}, Jens},
title = {On {COVID} {Trend} Lines},
date = {2021-01-30},
url = {https://doodles.mountainmath.ca/posts/2021-01-30-on-covid-trend-lines/},
langid = {en}
}